
끈기 있는 개발 공간
[ML] 비지도 학습 본문
오늘날 대부분의 머신러닝 애플리케이션이 지도 학습 기반이지만, 사용할 수 있는 데이터는 대부분 레이블이 없습니다. 즉, 입력 특성 $X$는 있지만 레이블 $y$는 없습니다.
8장에서는 가장 널리 사용되는 비지도 학습 방법인 차원 축소를 살펴봤습니다. 이 장에서는 몇 가지 비지도 학습과 알고리즘을 추가로 알아봅니다.
군집
등산하면서 이전에 본 적 없는 꽃을 발견했다고 가정해봅시다. 주위를 둘러보니 꽃이 몇 개 더 있고, 이들이 비슷해 보여 같은 종에 속한다는 걸 알았습니다. 어떤 종인지 알 수는 없지만 비슷해 보이는 꽃을 모으는 건 할 수 있습니다. 이를 군집이라고 합니다. 비슷한 샘플을 구별해 하나의 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업입니다.
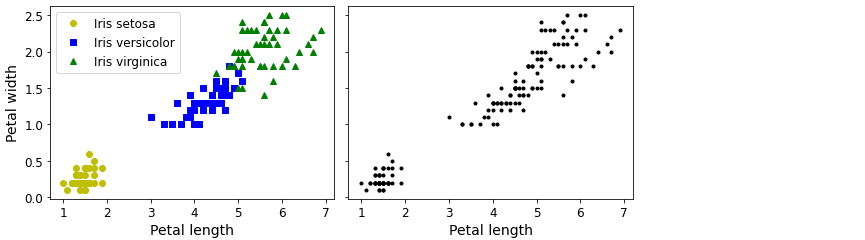
위의 그림을 보시면 왼쪽 붓꽃 데이터셋은 각 샘플의 품종이 구분되어 있습니다. 즉, 레이블이 되어 있습니다. 따라서, 분류 알고리즘이 잘 맞는 다는 걸 알 수 있습니다. 반면에, 오른쪽 데이터셋은 레이블이 없습니다. 따라서, 분류 알고리즘이 아닌 군집 알고리즘이 필요한 경우입니다.
군집 알고리즘을 사용하면 좌측 하단과 우측 상단, 두 개의 클러스터를 쉽게 감지할 수 있을 겁니다. 하지만 우측 상단 클러스터는 두 개의 하위 클러스터로 구성되었는지 확실하지는 않습니다. 사실 이 데이터셋은 보이지 않는 두 개의 특성이 더 있기 때문에 군집 알고리즘이 클러스터 세 개를 매우 잘 구분할 수 있습니다.
군집은 다음과 같은 다양한 애플리케이션에서 사용됩니다.
- 고객 분류
- 구매 이력이나 웹사이트 내 행동 등 기반 고객 클러스터 수집
- → 동일한 클러스터 내 사용자가 좋아하는 컨텐츠를 추천하는 추천 시스템
- 데이터 분석
- 새로운 데이터셋 분석할 때 각 클러스터를 따로 분석
- 차원 축소 기법
- 각 클러스터에 대한 샘플의 친화성 측정
- 친화성은 샘플이 클러스터에 얼마나 잘 맞는지를 측정
- 각 클러스터에 대한 샘플의 친화성 측정
- 이상치 탐지
- 모든 클러스터에 친화성이 낮은 샘플은 이상치일 가능성이 높음
- 제조 분야에서 결함을 감지할 때 유용
- 부정 거래 탐지에 활용
- 준지도 학습
- 레이블된 샘플이 적다면 군집 수행하여 동일한 클러스터에 있는 모든 샘플에 레이블 전파
- 지도 학습 알고리즘에 필요한 레이블이 크게 증가해 성능 향상
- 검색엔진
- 비슷한 이미지는 동일한 클러스터에 속함
- 사용자가 찾으려는 이미지를 제공하면 훈련된 군집 모델을 사용해 이미지의 클러스터를 찾아 이 클러스터의 모든 이미지를 반환
클러스터에 대한 보편적인 정의는 없습니다.
실제로 상황에 따라 다릅니다. 알고리즘이 다르면 다른 종류의 클러스터를 감지합니다.
- 어떤 알고리즘은 센트로이드라 부르는 특정 포인트를 중심으로 모인 샘플을 찾습니다.
- 어떤 알고리즘은 밀집되어 연속된 영역을 찾습니다.
- 이런 클러스터는 어떤 모양이든 될 수 있습니다.
- 어떤 알고리즘은 계층적으로 클러스터의 클러스터를 찾습니다.
k-평균
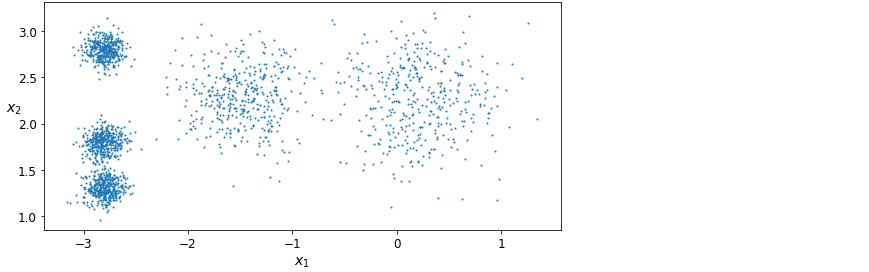
위와 같이 레이블 없는 데이터셋이 있습니다. k-평균은 반복 몇 번으로 이런 종류의 데이터셋을 빠르고 효율적으로 클러스터로 묶을 수 있는 간단한 알고리즘입니다. 로이드-포지 알고리즘이라고도 불립니다.
이 데이터셋에 k-평균 알고리즘을 훈련시켜봅시다.
import numpy as np
from sklearn.datasets import make_blobs
blob_centers = np.array(
[[ 0.2, 2.3],
[-1.5 , 2.3],
[-2.8, 1.8],
[-2.8, 2.8],
[-2.8, 1.3]])
blob_std = np.array([0.4, 0.3, 0.1, 0.1, 0.1])
X, y = make_blobs(n_samples=2000, centers=blob_centers,
cluster_std=blob_std, random_state=7)from sklearn.cluster import KMeans
k = 5
kmeans = KMeans(n_clusters=k)
y_pred = kmeans.fit_predict(X)KMeans 클래스의 인스턴스는 labels_ 인스턴스 변수에 훈련된 샘플의 레이블을 가지고 있습니다.

이 알고리즘이 찾은 센트로이드 다섯 개도 확인할 수 있습니다.
kmeans.cluster_centers_
새로운 샘플에 가장 가까운 센트로이드의 클러스터를 할당할 수 있습니다.
X_new = np.array([[0, 2], [3, 2], [-3, 3], [-3, 2.5]])
kmeans.predict(X_new) )
)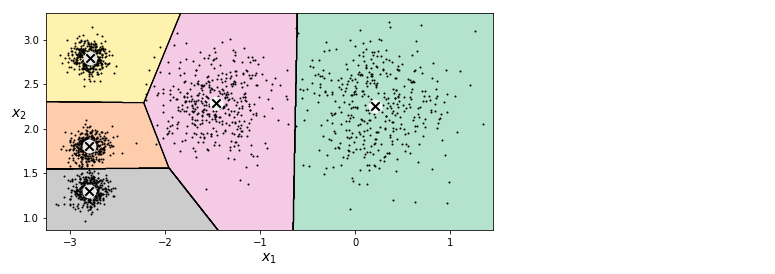
샘플은 클러스터에 할당할 때 센트로이드까지 거리를 고려하는 것이 전부이기 때문에 클러스터의 크기가 많이 다르면 알고리즘이 잘 작동하지 않습니다.
하드 군집이라는 샘플을 하나의 클러스터에 할당하는 것보다 클러스터마다 샘플에 점수를 부여하는 게 유용할 수 있습니다. 이를 소프트 군집이라고 합니다. 이 점수는 샘플과 센트로이드 사이의 거리가 될 수 있습니다. KMeans 클래스의 transform() 메서드는 샘플과 각 센트로이드 사이의 거리를 반환합니다.
kmeans.transform(X_new)
고차원 데이터셋을 이런 방식으로 변환하면 k-차원 데이터셋이 만들어집니다. 이 변환은 매우 효율적인 비선형 차원 축소 기법이 될 수 있습니다.
작동 원리
센트로이드가 주어진다고 가정해봅시다. 데이터셋에 있는 모든 샘플에 가장 가까운 센트로이드의 클러스터를 할당할 수 있습니다. 반대로 모든 샘플의 레이블이 주어진다면 각 클러스터에 속한 샘플의 평균을 계산하여 모든 센트로이드를 쉽게 구할 수 있습니다. 하지만 레이블이나 센트로이드가 주어지지 않는다면 어떻게 해야 할까요?
- 센트로이드를 랜덤하게 선정
- 예를 들어, 무작위로 $k$개의 샘플을 뽑아 그 위치를 센트로이드로 정함
- 샘플에 레이블을 할당하고 센트로이드 업데이트
- 센트로이드에 변화가 없을 때까지 계속 진행
이 알고리즘은 제한된 횟수 안에 수렴하는 걸 보장합니다. 일반적으로 이 횟수는 매우 작을 것이며, 무한하게 반복되지 않을 겁니다. 샘플과 가장 가까운 센트로이드 사이의 평균 제곱 거리가 매 단계마다 작아질 수밖에 없기 때문입니다.
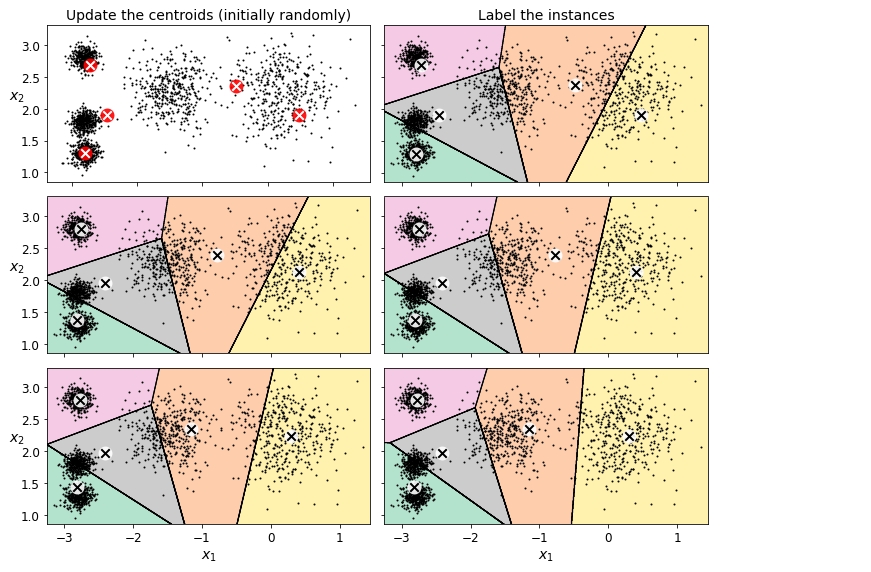
위 그림에서 이 알고리즘이 작동하는 걸 볼 수 있습니다.
- (왼쪽 위) 센트로이드를 랜덤하게 초기화합니다.
- (오른쪽 위) 샘플에 레이블을 할당합니다.
- (왼쪽 가운데) 센트로이드를 업데이트 합니다.
- (오른쪽 가운데) 샘플에 다시 레이블을 할당합니다.
- 반복
여기서 볼 수 있듯이 반복 세 번 만에 이 알고리즘은 최적으로 보이는 클러스터에 도달했습니다.
이 알고리즘의 계산 복잡도는 일반적으로 샘플 개수 $m$, 클러스터 개수 $k$, 차원 개수 $n$에 선형적입니다. 하지만 데이터가 군집할 수 있는 구조를 가질 때 한정이며, 그렇지 않으면 최악의 경우 계산 복잡도는 샘플 개수가 지수적으로 급격히 증가할 수 있습니다. 하지만, 실전에서 이런 일은 드뭅니다. 일반적으로 k-평균은 가장 빠른 군집 알고리즘 중 하나입니다.
이 알고리즘이 수렴하는 게 보장되지만 이 여부는 센트로이드 초기화에 달려 있습니다.
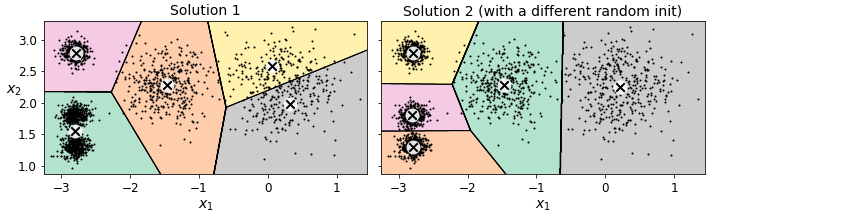
위 그림은 랜덤한 초기화 단계에서 운이 없을 때 알고리즘이 수렴할 수 있는 최적이 아닌 솔루션의 두 예입니다.
센트로이드 초기화를 개선하여 이런 위험을 줄일 수 있는 방법을 알아봅시다.
센트로이드 초기화 방법
센트로이드 위치를 근사하게 알 수 있다면 init 매개변수에 센트로이드 리스트를 담은 넘파이 배열을 지정하고 n_init를 1로 설정할 수 있습니다.
good_init = np.array([[-3, 3], [-3, 2], [-3, 1], [-1, 2], [0, 2]])
kmeans = KMeans(n_clusters=5, init=good_init, n_init=1)또 다른 방법은 랜덤 초기화를 다르게 하여 여러 번 알고리즘을 실행하고 가장 좋은 솔루션을 선택하는 겁니다. 랜덤 초기화 횟수는 n_init 매개 변수로 조절하며, 기본값은 10입니다. 이는 fit() 메서드를 호출할 때 앞서 설명한 전체 알고리즘이 10번 실행된다는 뜻입니다. 사이킷런은 이 중에 최선의 솔루션을 반환합니다.
최선의 솔루션을 찾기 위한 성능 지표가 있습니다. 이 값은 각 샘플과 가장 가까운 센트로이드 사이의 제곱 거리 합이며 모델의 이너셔(intertia)라고 부릅니다. 앞의 그림에서 왼쪽 모델의 이너셔는 대략 223.3이고 오른쪽에 있는 모델의 이너셔는 237.5입니다. KMeans 클래스는 알고리즘을 n_init번 실행하여 이너셔가 가장 낮은 모델을 반환합니다. 이 값이 궁금하면 inertia_ 인스턴스 변수로 모델의 이너셔를 확인할 수 있습니다.
kmeans.inertia_score() 메서드는 이너셔의 음숫값을 반환합니다. 1장부터 학습을 해왔다면 왜 음수인지 추측할 수 있을 겁니다. ‘큰 값이 좋은 것이다’라는 규칙을 따라야 하기 때문입니다.
kmeans.score(X)k-평균++ 알고리즘
데이비드 아서와 세르게이 바실비츠키가 2006년 논문에서 제안한 알고리즘입니다. 이 논문에서는 다른 센트로이드와 거리가 먼 센트로이드를 선택하는 똑똑한 초기화 단계를 소개했습니다. 이 방법은 앞서 문제 제시한 k-평균 알고리즘이 최적인 아닌 솔루션으로 수렴할 가능성을 크게 낮춥니다.
- 데이터셋에서 무작위로 균등하게 하나의 센트로이드를 선택합니다.
- 특정 확률로 샘플을 새로운 센트로이드로 선택합니다. 이 확률 분포는 이미 선택한 센트로이드에서 멀리 떨어진 샘플을 다음 센트로이드로 선택할 가능성을 높입니다.
- k개의 센트로이드가 선택될 때까지 이전 단계를 반복합니다.
KMeasn 클래스는 기본적으로 이 초기화 방법을 사용합니다. 원래 방식을 사용하고 싶다면 init 매개변수를 “random”으로 지정합니다. 근데 굳이 이렇게 할 필요는 없겠죠?
k-평균 속도 개선과 미니배치 k-평균
2013년 찰스 엘칸의 논문에서 k-평균 알고리즘에 대해 또 다른 중요한 개선을 제안했습니다. 불필요한 거리 계산을 많이 피함으로써 알고리즘의 속도를 상당히 높일 수 있습니다. 엘칸은 이를 위해 삼각 부등식을 사용했습니다. 그리고 샘플과 센트로이드 사이의 거리를 위한 하한선과 상한선을 유지합니다. 이 알고리즘은 KMeans 클래스에서 기본으로 사용합니다. 원래 알고리즘을 사용하려면 algorithm 매개변수를 “full”로 지정합니다.
근데 이것도 굳이…
2010년 데이비드 스컬리의 논문에서 k-평균 알고리즘의 또 다른 중요한 변종이 제시되었습니다. 전체 데이터셋을 사용해 반복하지 않고 이 알고리즘은 각 반복마다 미니배치를 사용해 센트로이드를 조금씩 이동합니다. 이는 일반적으로 알고리즘의 속도를 3배에서 4배 정도 높입니다. 또한 메모리에 들어가지 않는 대량의 데이터셋에 군집 알고리즘을 적용할 수 있습니다. 사이킷런은 MiniBatchKMeans 클래스에 이 알고리즘을 구현했습니다. KMeans 클래스처럼 이 클래스를 사용할 수 있습니다.
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(n_clusters=5)
minibatch_kmeans.fit(X)데이터셋이 메모리에 들어가지 않으면 memmap 클래스를 사용합니다. 또는 MiniBatchKMeans 클래스의 partial_fit() 메서드에 한 번에 하나의 미니배치를 전달할 수 있습니다. 하지만 초기화를 여러 번 수행하고 만들어진 결과에서 가장 좋을 것을 직접 골라야 해서 해야 할 일이 많습니다.
최적의 클러스터 개수 찾기
일반적으로 $k$를 어떻게 설정할 지 쉽게 알 수 없습니다. 가장 작은 이너셔를 가진 모델을 선택하면 될 거 같지만 그렇게 간단하지는 않습니다. 이너셔는 $k$가 증가함에 따라 점점 작아지므로 $k$를 선택할 때 좋은 성능 지표가 아닙니다.
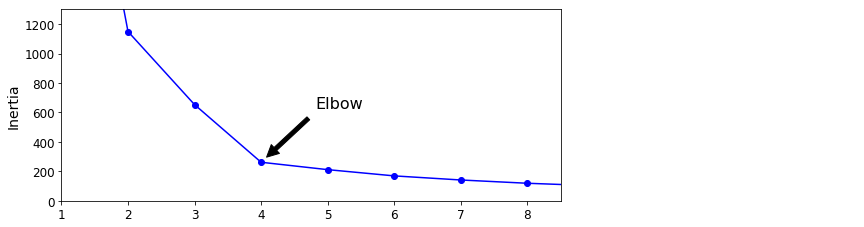
위 그림은 $k$에 대한 이너셔의 함수를 나타내는 그래프입니다. 이너셔는 $k$가 4까지 증가할 때 빠르게 줄어드므로 $k=4$ 지점이 엘보입니다. 따라서 $k$에 대한 정답을 모른다면 4는 좋은 선택이 됩니다.
하지만 최선의 클러스터 개수를 선택하는 이 방법은 너무 엉성합니다. 더 정확한 방법은 실루엣 점수입니다. 이 값은 모든 샘플에 대한 실루엣 계수의 평균입니다. 샘플의 실루엣 계수는 $(b-a)/max(a,b)$로 계산합니다. 여기에서 $a$는 동일한 클러스터에 있는 다른 샘플까지 평균 거리입니다. $b$는 가장 가까운 클러스터까지 평균 거리입니다.
- 샘플과 가장 가까운 클러스터는 자신이 속한 클러스터는 제외하고 $b$가 최소인 클러스터임
- -1 ≤ 실루엣 계수 ≤ 1
- 실루엣 계수가 1에 가깝다는 의미
- 자신의 클러스터 안에 잘 속해 있음
- 다른 클러스터와는 멀리 떨어져 있음
- 실루엣 계수가 0에 가깝다는 의미
- 클러스터 경계에 위치
- 실루엣 계수가 -1에 가깝다는 의미
- 이 샘플이 잘못된 클러스터에 할당되었다는 의미
실루엣 점수를 계산하려면 사이킷런의 silhouette_score() 함수를 사용합니다.
from sklearn.metrics import silhouette_score
silhouette_score(X, kmeans.labels_) )
)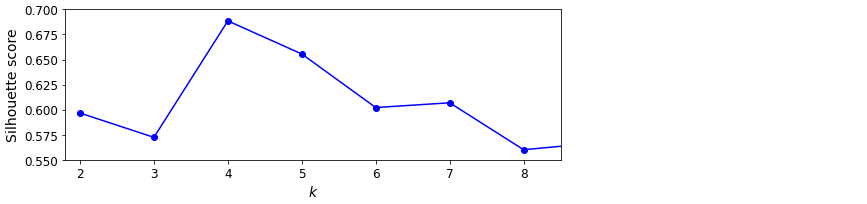
클러스터 개수를 달리하여 실루엣 점수를 비교해볼 때 $k=4$가 좋은 선택이지만 $k=5$도 꽤 좋다는 사실을 잘 보여줍니다.
k-평균의 한계
k-평균은 장점이 많습니다. 특히 속도가 빠르고 확장이 용이합니다. 그렇지만 k-평균 꽤 번거로운 작업을 수반하기도 합니다.
- 최적인 아닌 솔루션을 피하려면 알고리즘을 여러 번 실행해야 함
- 클러스터 개수를 지정해야 함
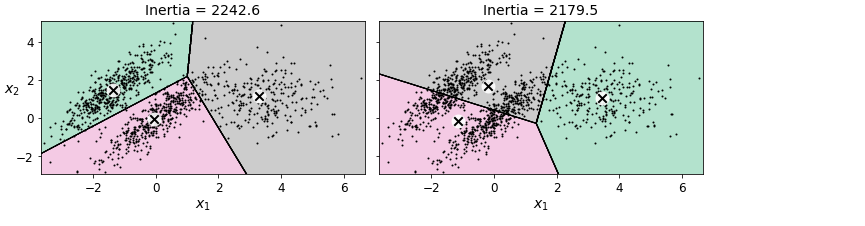
또한, 위 그림에서 보이듯이 k-평균은 클러스터의 크기나 밀집도가 서로 다르거나 원형이 아닐 경우 잘 작동하지 않습니다. 데이터에 따라서 잘 수행할 수 있는 군집 알고리즘이 다릅니다. 이런 타원형 클러스터에서는 가우시안 혼합 모델이 잘 작동합니다.
그러므로 k-평균을 실행하기 전에 입력 특성의 스케일을 맞추는 게 중요합니다. 특성의 스케일을 맞추어도 모든 클러스터가 잘 구분되고 원형의 형태를 가진다고 보장할 수는 없지만 일반적으로 더 좋아집니다.
군집을 사용한 이미지 분할
이미지 분할은 이미지를 세그먼트 여러 개로 분할하는 작업입니다. 시맨틱 분할에서는 동일한 종류의 물체에 속한 모든 픽셀은 같은 세그먼트에 할당됩니다. 예를 들어 자율 주행 자동차의 비전 시스템에서 보행자 이미지를 구성하는 모든 픽셀은 보행자 세그먼트에 할당될 겁니다. 이 경우 각 보행자는 다른 세그먼트가 될 수 있는데, 이런 분할을 인스턴스 분할이라고 부릅니다. 시맨틱 또는 인스턴스 분할에서 최고 수준의 성능을 내려면 합성곱 신경망을 사용한 복잡한 모델을 사용해야 합니다. 여기서는 훨씬 쉬운 작업인 색상 분할을 수행해보겠습니다.
동일한 색상을 가진 픽셀을 같은 세그먼트에 할당할 겁니다.
import os
from matplotlib.image import imread
image = imread(os.path.join("images", "unsupervised_learning", "ladybug.png"))
image.shape
다음 코드는 이 배열을 RGB 색상의 긴 리스트로 변환한 다음 k-평균을 사용해 이 색상을 클러스터로 모읍니다.
X = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=8).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
segmented_img = segmented_img.reshape(image.shape)
군집을 사용한 전처리
군집은 지도 학습 알고리즘을 적용하기 전에 전처리 단계로 사용할 수 있습니다. 비교를 위해 먼저 지도학습을 진행해보겠습니다.
from sklearn.datasets import load_digits
X_digits, y_digits = load_digits(return_X_y=True)from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_digits, y_digits)from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)log_reg.score(X_test, y_test)
이제 k-평균을 전처리 단계로 사용했을 때 성능이 더 좋아지는지 확인해보겠습니다.
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
("kmeans", KMeans(n_clusters=50)),
("log_reg", LogisticRegression()),
])
pipeline.fit(X_train, y_train)pipeline.score(X_test, y_test)
아니 분명 책에서는 더 좋아졌는데…???
log_reg.score(X_test, y_test)
pipeline.score(X_test, y_test)
train_test_split() 메서드의 random_state를 42로 고정하고 다시 시도해보니 성능이 더 좋아졌습니다.
군집이 데이터셋의 차원을 64에서 50으로 감소시켰지만 성능 향상은 대부분 변환된 데이터셋이 원본 데이터셋보다 선형적으로 더 잘 구분할 수 있기 때문입니다. 따라서 로지스틱 회귀를 사용하기에 더 좋습니다. 하지만, 어디까지나 일반적인 성능 향상을 기대한다는 것이고, 앞서 본 것처럼 여러 요인에 의해 어떤 경우에는 성능이 더 나빠질 수도 있다는 걸 알고 넘어가야겠습니다.
위에서는 클러스터 개수 $k$를 임의로 정했습니다. 따라서 최적의 $k$를 찾아 이보다 더 성능을 높일 수 있습니다. k-평균이 분류 파이프라인의 하나의 전처리 단계이기 때문에 앞에서 배웠던 것처럼 실루엣 분석을 하거나 이너셔가 감소되는 확인할 필요가 없습니다. 가장 좋은 $k$값은 교차 증에서 가장 좋은 분류 성능을 내는 값입니다. GridSearchCV를 사용해 최적의 클러스터 개수를 찾아봅시다.
grid_clf.best_params_
왜 이러는 걸까요?
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000)
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test)
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
("kmeans", KMeans(n_clusters=50)),
("log_reg", LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000)),
])
pipeline.fit(X_train, y_train)
pipeline.score(X_test, y_test)
from sklearn.model_selection import GridSearchCV
param_grid = dict(kmeans__n_clusters=range(2, 100))
grid_clf = GridSearchCV(pipeline, param_grid, cv=3, verbose=2)
grid_clf.fit(X_train, y_train)
handson-ml2/09_unsupervised_learning.ipynb at master · rickiepark/handson-ml2
위 주소를 참고하여 LogisticRegression의 params 셋팅을 같게 해주니 책에서 제시하는 것과 비슷한 결과를 얻을 수 있었습니다. 위 결과에 무슨 요인이 작용하는 건지는 해결해야 할 과제 같습니다.
군집을 사용한 준지도 학습
군집을 사용하는 또 다른 사례는 준지도 학습입니다. 숫자 데이터셋에서 레이블된 50개 샘플에 로지스틱 회귀 모델을 훈련해보겠습니다.
n_labeled = 50
log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000, random_state=42)
log_reg.fit(X_train[:n_labeled], y_train[:n_labeled])log_reg.score(X_test, y_test)
어떻게 개선할 수 있을 지 알아봅시다.
- 훈련 세트를 50개의 클러스터로 모음
- 각 클러스터에서 센트로이드에 가장 가까운 이미지를 찾음
- 이런 이미지를 대표 이미지라 부름
- 이미지를 보고 수동으로 레이블을 할당
k = 50
kmeans = KMeans(n_clusters=k)
X_digits_dist = kmeans.fit_transform(X_train)
representative_digit_idx = np.argmin(X_digits_dist, axis=0)
X_representative_digits = X_train[representative_digit_idx]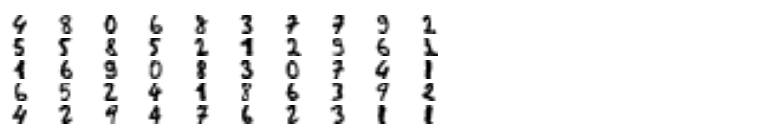
y_representative_digits = np.array([
4, 8, 0, 6, 8, 3, 7, 7, 9, 2,
5, 5, 8, 5, 2, 1, 2, 3, 6, 1,
1, 6, 3, 0, 8, 3, 0, 7, 4, 1,
6, 5, 2, 4, 1, 8, 6, 3, 9, 2,
4, 2, 9, 4, 7, 6, 2, 3, 1, 1
])log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000, random_state=42)
log_reg.fit(X_representative_digits, y_representative_digits)
log_reg.score(X_test, y_test)
2% 가량 성능이 개선되었습니다. 샘플에 레이블을 부여하는 것은 비용이 많이 들고 어렵습니다. 특히 전문가가 수동으로 처리해야 할 때 그렇습니다. 따라서 무작위 샘플 대신 대표 샘플에 레이블을 할당하는 게 좋은 방법입니다.
여기서 한 단계 더 나아가서 이 레이블을 동일한 클러스터에 있는 모든 샘플로 전파하면 어떨까요? 이를 레이블 전파라고 부릅니다.
y_train_propagated = np.empty(len(X_train), dtype=np.int32)
for i in range(k):
y_train_propagated[kmeans.labels_==i] = y_representative_digits[i]log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000, random_state=42)
log_reg.fit(X_train, y_train_propagated)
log_reg.score(X_test, y_test)
여기에는 클러스터 경계에 가깝게 위치한 샘플이 포함되어 있고 아마 잘못 레이블이 부여되었을 겁니다. 센트로이드와 가까운 샘플의 20%에만 레이블을 전파해보고 어떻게 되는지 확인해봅시다.
percentile_closest = 20
X_cluster_dist = X_digits_dist[np.arange(len(X_train)), kmeans.labels_]
for i in range(k):
in_cluster = (kmeans.labels_ == i)
cluster_dist = X_cluster_dist[in_cluster]
cutoff_distance = np.percentile(cluster_dist, percentile_closest)
above_cutoff = (X_cluster_dist > cutoff_distance)
X_cluster_dist[in_cluster & above_cutoff] = -1
partially_propagated = (X_cluster_dist != -1)
X_train_partially_propagated = X_train[partially_propagated]
y_train_partially_propagated = y_train_propagated[partially_propagated]log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000, random_state=42)
log_reg.fit(X_train_partially_propagated, y_train_partially_propagated)
log_reg.score(X_test, y_test)
* 능동 학습
능동 학습은 알고리즘이 요청할 때 특정 샘플의 레이블을 제공합니다. 이를 몇 번 반복하여 모델과 훈련세트를 지속적으로 향상시킬 수 있습니다. 능동 학습에는 여러 전략이 있지만 가장 널리 사용되는 것 중 하나가 불확실성 샘플링입니다. 작동 방식은 다음과 같습니다.
- 지금까지 수집한 레이블된 샘플을 사용하여 모델을 훈련합니다. 이 모델을 사용해 레이블되지 않은 모든 샘플에 대한 예측을 만듭니다.
- 모델이 가장 불확실하게 예측한 샘플을 전문가에게 보내 레이블을 붙입니다. 즉, 이는 능동 학습에서 알고리즘이 요청하여 특정 샘플의 레이블을 제공 받는 것에 해당합니다.
- 레이블을 부여하는 노력만큼의 성능이 향상되지 않을 때까지 이를 반복합니다.
DBSCAN
이 알고리즘은 국부적인 밀집도를 추정하는 매우 다른 방식을 사용합니다. 이 방식으로 임의의 모양을 가진 클러스터를 식별할 수 있습니다. DBSCAN은 밀집된 연속적 지역을 클러스터로 정의합니다. 작동 방식은 다음과 같습니다.
- 알고리즘이 각 샘플에서 작은 거리인 $\varepsilon$ 내에 샘플이 몇 개 놓여 있는지 셉니다. 이 지역을 샘플의 $\varepsilon$-이웃이라고 부릅니다.
- 자기 자신을 포함해 $\varepsilon$-이웃 내에 적어도
min_samples개 샘플이 있다면 이를 핵심 샘플로 간주합니다. - 핵심 샘플의 이웃에 있는 모든 샘플은 동일한 클러스터에 속합니다. 이웃에는 다른 핵심 샘플이 포함될 수 있습니다. 따라서 핵심 샘플의 이웃의 이웃은 계속해서 하나의 클러스터를 형성합니다.
이 알고리즘은 모든 클러스터가 충분히 밀집되어 있고 밀집되지 않은 지역과 잘 구분될 때 좋은 성능을 냅니다. 사이킷런에 있는 DBSCAN 클래스는 사용법이 간단합니다. 반달 모양 데이터셋에서 테스트해보겠습니다.
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05)
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)dbscan.labels_
일부 샘플의 클러스터 인덱스는 -1입니다. 이는 알고리즘이 이 샘플을 이상치로 판단했다는 의미입니다. 핵심 샘플의 인덱스는 인스턴스 변수는 core_sample_indices_ 에서 확인할 수 있습니다. 핵심 샘플 자체는 인스턴스 변수 components_ 에 저장되어 있습니다.
len(dbscan.core_sample_indices_)
dbscan.core_sample_indices_
dbscan.components_ )
)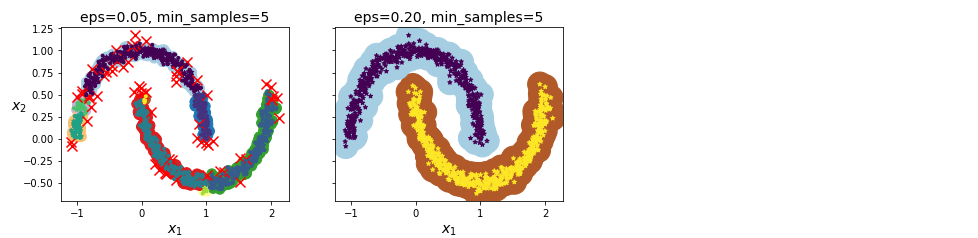
이 군집의 결과가 위 그림의 왼쪽 그래프에 있습니다. 클러스터를 7개 만들었고 많은 샘플을 이상치로 판단했습니다. eps를 0.2로 증가시켜 샘플의 이웃 범위를 넓히면 오른쪽 그래프처럼 완벽한 군집을 얻습니다. 이 모델로 계속 진행해봅시다.
DBSCAN 클래스는 predict() 메서드를 제공하지 않고 fit_predict() 메서드를 제공합니다. 다시 말해 이 알고리즘은 새로운 샘플에 대해 클러스터를 예측할 수 없습니다. 이런 구현을 결정하게 된 건 다른 분류 알고리즘이 이런 작업을 더 잘 수행할 수 있기 때문입니다. 따라서 사용자가 필요한 예측기를 선택해야 합니다. 예를 들어 KNeighborsClassifier를 훈련해봅시다.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=50)
knn.fit(dbscan.components_, dbscan.labels_[dbscan.core_sample_indices_])이제 샘플 몇 개를 전달하여 어떤 클러스터에 속할 가능성이 높은지 예측하고 각 클러스터에 대한 확률을 추정해봅시다.
X_new = np.array([[-0.5, 0], [0, 0.5], [1, -0.1], [2, 1]])
knn.predict(X_new)
knn.predict_proba(X_new)
이 분류기를 핵심 샘플에서만 훈련했지만 모든 샘플에서 훈련할 수도 있습니다. 또는 이상치를 제외할 수 있습니다. 이 결정 경계가 아래 그림에 나타나 있습니다. 훈련 세트에 이상치가 없기 때문에 클러스터가 멀리 떨어져 있더라도 분류기는 항상 클러스터 한 개를 선택합니다. 최대 거리를 사용하면 두 클러스터에서 멀리 떨어진 샘플을 이상치로 간단히 분류할 수 있습니다. KNeighborsClassifier의 kneighbors() 메서드를 사용합니다. 이 메서드에 샘플을 전달하면 훈련 세트에서 가장 가까운 $k$개이 이웃의 거리와 인덱스를 반환합니다.
y_dist, y_pred_idx = knn.kneighbors(X_new, n_neighbors=1)
y_pred = dbscan.labels_[dbscan.core_sample_indices_][y_pred_idx]
y_pred[y_dist > 0.2] = -1
y_pred.ravel() )
)
DBSCAN은 매우 간단하지만 강력한 알고리즘입니다. 클러스터의 모양과 개수에 상과없이 감지할 수 있는 능력이 있습니다. 이상치에 안정적이고 하이퍼파라미터가 eps, min_samples 두 개뿐입니다. 하지만 클러스터 간의 밀집도가 크게 다르면 모든 클러스터를 올바르게 잡아내는 것이 불가능합니다. 계산 복잡도는 대략 $O(m\log m)$입니다. 샘플 개수에 대해 거의 선형적으로 증가하지만 사이킷런의 구현은 eps가 커지면 $O(m^2)$만큼 메모리가 필요합니다.
다른 군집 알고리즘
병합 군집
클러스터 계층을 밑바닥부터 위로 쌓아 구성합니다. 물 위를 떠다니는 작은 물방울이 점차 붙어 나중에는 하나의 커다란 방울이 되는 것처럼 반복마다 병합 군집은 인접한 클러스터 쌍을 연결합니다. 병합된 클러스터 쌍을 트리로 모두 그리면 클러스터의 이진 트리를 얻을 수 있습니다. 이 트리의 리프는 개별 샘플입니다. 병합 군집의 주요 특징은 다음과 같습니다.
- 병합 군집은 대규모 샘플과 클러스터에 잘 확장되며 다양한 형태의 클러스터를 감지할 수 있습니다.
- 특정 클러스터 개수를 선택하는 데 도움이 되는 유용한 클러스터 트리를 만들 수 있습니다.
- 이웃한 샘플 간의 거리를 담은 $m\times m$ 크기 희소 행렬을 연결 행렬로 전달하는 식으로 대규모 샘플에도 잘 적용할 수 있습니다. 연결 행렬이 없으면 대규모 데이터셋으로 확장하기 어렵습니다.
BIRCH
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies) 알고리즘은 특별히 대규모 데이터셋을 위해 고안되었습니다. 특성 개수가 너무 많지 않다면 배치 k-평균보다 빠르고 비슷한 결과를 만듭니다. 훈련 과정에서 새로운 샘플을 클러스터에 빠르게 할당할 수 있는 정보를 담은 트리 구조를 만듭니다. 이 트리에 모든 샘플을 저장하지 않습니다. 이 방식은 제한된 메모리를 사용해 대용량 데이터셋을 다룰 수 있습니다.
평균-이동
- 각 샘플을 중심으로 하는 원을 그립니다.
- 원마다 안에 포함된 모든 샘플의 평균을 구합니다.
- 원의 중심을 평균점으로 이동시킵니다. 모든 원이 움직이지 않을 때까지 이 평균-이동을 계속합니다. 평균-이동은 지역의 최대 밀도를 찾을 때까지 높은 쪽으로 원을 이동시킵니다. 동일한 지역에 안착한 원에 있는 모든 샘플은 동일한 클러스터가 됩니다.
* 평균-이동 vs DBSCAN
이 둘은 모양이나 개수에 상관없이 클러스터를 찾을 수 있다는 점, 하이퍼파라미터가 매우 적다는 점, 국부적인 밀집도 추정에 의존한다는 점이 비슷합니다. 하지만 평균-이동은 DBSCAN과 달리 클러스터 내부 밀집도가 불균형할 때 여러 개로 나뉘는 경향이 있습니다. 계산 복잡도가 $O(m^2)$이므로 대규모 데이터셋에는 적합하지는 않습니다.
유사도 전파
이 알고리즘은 투표 방식을 사용합니다. 샘플은 자신을 대표할 수 있는 비슷한 샘플에 투표합니다. 알고리즘이 수렴하면 각 대표와 투표한 샘플이 클러스터를 형성합니다. 유사도 전파는 크기가 다른 여러 개의 클러스터를 감지할 수 있습니다. 계산 복잡도가 $O(m^2)$이므로 대규모 데이터셋에는 적합하지는 않습니다.
스펙트럼 군집
이 알고리즘은 샘플 사이의 유사도 행렬을 받아 차원을 축소합니다(저차원 임베딩을 만듭니다). 그 다음 이 저차원 공간에서 또 다른 군집 알고리즘을 사용합니다. 스펙트럼 군집은 복잡한 클러스터 구조를 감지하고 그래프 컷을 찾는 데 사용할 수 있습니다. 이 알고리즘은 샘플 개수가 많으면 잘 적용되지 않고 클러스터의 크기가 매우 다르면 잘 작동하지 않습니다.
가우시안 혼합
가우시안 혼합 모델(Gaussian Mixture Model)은 샘플이 파라미터가 알려지지 않은 여러 개의 혼합된 가우시안 분포에서 생성되었다고 가정하는 확률 모델입니다. 다음과 같은 특징이 있습니다.
- 하나의 가우시안 분포에서 생성된 모든 샘플은 하나의 클러스터를 형성합니다. 일반적으로 이 클러스터는 타원형입니다.
- 각 클러스터는 타원의 모양, 크기, 밀집도, 방향이 다릅니다.
- 샘플이 주어지면 가우시안 분포 중 하나에서 생성되었다는 것을 압니다. 하지만 어떤 분포인지 또 이 분포의 파라미터는 무엇인지 알 수 없습니다.
여러 GMM 변종이 있으며 가장 간단한 버전이 GaussianMixture 클래스에 구현되어 있습니다. 여기에서는 사전에 가우시안 분포의 개수 $k$를 알아야 합니다. 데이터셋 $\mathbf{X}$가 다음 확률 과정을 통해 생성되었다고 가정합니다.
- 샘플마다 $k$개의 클러스터에서 랜덤하게 한 클러스터가 선택됩니다. $j$번째 클러스터를 선택할 확률은 클러스터의 가중치 $\phi ^{(j)}$로 정의됩니다. $i$번째 샘플을 위해 선택한 클러스터 인덱스는 $z ^{(i)}$로 표시합니다.
- $z ^{(i)}=j$이면, 즉 $i$번째 샘플이 $j$번째 클러스터에 할당되었다면 이 샘플의 위치 $\mathbf{x} ^{(i)}$는 평균이 $\mu ^{(j)}$이고 공분산 행렬이 $\Sigma ^{(j)}$인 가우시안 분포에서 랜덤하게 샘플링됩니다. 이를 $\mathbf{x} ^{(i)}\sim \mathcal{N}(\phi^{(j)},\Sigma^{(j)})$와 같이 씁니다.
이 생성 과정은 그래프 모형으로 나타낼 수 있습니다. 이는 책에 있는 그림 9-16을 참고합니다.
먼저 데이터셋 $\mathbf{X}$가 주어지면 가중치 $\Phi$와 전체 분포의 파라미터 $\mu ^{(1)}$에서 $\mu ^{(k)}$까지와 $\Sigma ^{(1)}$에서 $\Sigma ^{(k)}$까지를 추정합니다. 사이킷런의 GaussianMixture 클래스를 사용하면 아주 쉽습니다.
from sklearn.mixture import GaussianMixture
gm = GaussianMixture(n_components=3, n_init=10)
gm.fit(X)이 알고리즘이 추정한 파라미터를 확인해봅시다.
gm.weights_
gm.means_
gm.covariances_
이 클래스는 기댓값-최대화(EM) 알고리즘을 사용합니다. 이 알고리즘은 k-평균 알고리즘과 공통점이 많습니다.
'ML' 카테고리의 다른 글
| [ML] 차원 축소 (0) | 2024.07.19 |
|---|---|
| [ML] 앙상블 학습과 랜덤 포레스트 (0) | 2024.07.19 |
| [ML] 결정트리 (0) | 2024.07.19 |
| [ML] 서포트 벡터 머신 (0) | 2024.07.19 |
| [ML] 모델 훈련 (2) | 2024.07.19 |